用Raspberry Pi寫Python網路爬蟲 — (2) 安裝衰敗的selenium
前言
上回,我們在raspberry pi上安裝了python的環境,並用macbook ssh連線到pi來寫code。看起來真有那麼點意思,好像可以來爬蟲了!耶依!
爬蟲菜雞如我雖然最愛用的還是 requests.get() 加上 BeautifulSoup() ,最後用CSS Selector或find_All()暴力找出所要的物件…
不過有時碰上了java script或者有user interface的網頁,由於功力實在太淺,只好搬出selenium大法。
雖說在小小的raspberry pi上跑瀏覽器實在不是個好主意,不過用pi爬蟲就是用長時間的運作來交換效益嘛…下面就來試試看挑戰安裝selenium吧!(殊不知開啟了三個小時的debug地獄…)
前置準備
我們需要備齊:
- chromium-browser (就是chrome)
- webdriver(就是chrome driver)
- selenium
安裝指令
實際上,這步驟異常的簡單,也無須到chrome driver的官方網站去找對應版本的driver,只要在terminal輸入指令就好:
sudo apt-get install chromium-browser #還沒有安裝瀏覽器的才需要這行
sudo apt-get install chromium-chromedriver #會自動找對應的版本
sudo pip3 install selenium


以上的程式碼參考了:
https://www.itdaan.com/tw/7903e5a1537f27c83839c72777737879
這行指令可以幫我們確認安裝路徑,等等在python中的code要告訴電腦說driver在哪裡:
dpkg -L chromium-chromedriverSo far so good, 理論上來說這樣就大功告成了,只要在jupyter notebook中記得寫上:
driver_path = “/usr/lib/chromium-browser/chromedriver”
browser = webdriver.Chrome(driver_path)就可以了讓python確實控制pi裡迷你瀏覽器chromium了(鼓掌
使用selenium
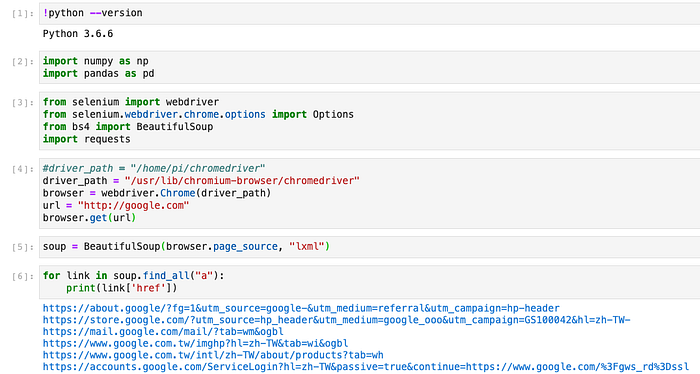
完整的程式碼如下:
# 套件
from selenium import webdriver
from bs4 import BeautifulSoup# 設定driver路徑
driver_path = "/usr/lib/chromium-browser/chromedriver"
browser = webdriver.Chrome(driver_path)# 目標網站
url = "http://google.com"
browser.get(url)# 取得html原始碼
soup = BeautifulSoup(browser.page_source, "lxml")
# 解析連結
for link in soup.find_all("a"):
print(link['href'])
可能會出現的Bug及修復的方式
事實上,在最開始時,我沒有辦法正確地使用get()這個函式,因此花了很多時間debug。最後莫名其妙地解決了,但為了避免有遇到跟我相同問題的人走太多冤枉路,因此大致提供我做了什麼(但我仍舊不明白原因):
- 先看到這篇,關於no_proxy環境變數的問題
https://stackoverflow.com/questions/7347494/selenium-webdriver-geturl-does-not-open-the-url - 再看到這篇,用deconfig-editor來改環境變數
https://askubuntu.com/questions/11274/setting-up-proxy-to-ignore-all-local-addresses
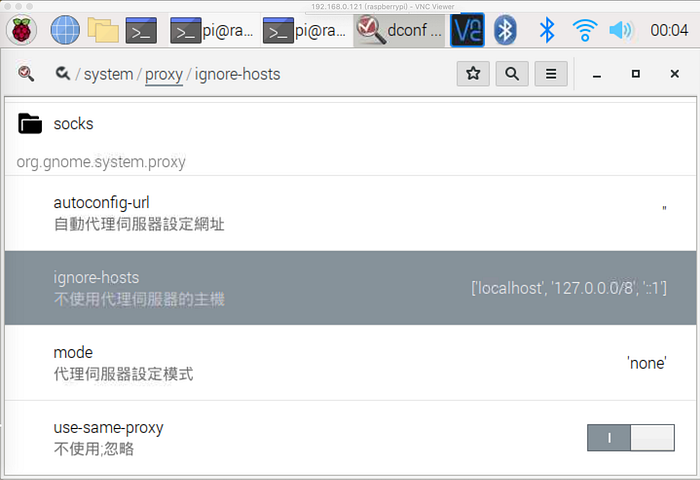
然後就okay了,不過當我把環境變數再改回default的時候仍然可行。因此原因不明QQ
下一回筆記應該就是寫寫怎樣爬新聞網站裡的新聞了,希望可以寫得言簡意賅點QQ
